Differential Privacy: Lessons for Enterprises from U.S. Government Agencies
• read

Differential privacy is considered perhaps the only viable and formal way of publicly releasing information or allowing queries or analysis on data while protecting the privacy of the individuals represented in the data.
—Amol Deshpande, WireWheel
Enterprises trying to keep a rapidly changing regulatory landscape can benefit from looking at how their public sector counterparts have leveraged technological advances to publish data while respecting the privacy of individuals. While most organizations are not looking to publish data publicly, differential privacy can also enable internal data sharing between departments that are otherwise prescribed by regulation where accuracy or fitness for use of personal data is just as important. It is eminently translatable into commercial settings.
To discuss how differential privacy is being used, a group of experts met at the 2022 Summer Spokes Technology Conference (held June 22-23) to present their experiences in both academic and commercial settings.
The panel Differential Privacy: Lessons for Enterprises from U.S. Government Agencies was hosted by WireWheel Chief Scientist and Co-Founder Amol Deshpande. He was joined by the Co-Founders of Tumult Labs, CEO Gerome Miklau and Chief Scientist Ashwin Machanavajjhala, and Urban Institute Principal Research Associate and Statistical Methods Group Lead, Claire McKay Bowen.
Balancing insights with protection
Differential privacy technology seeks to solve the problem of balancing acquiring insights into groups of people while protecting facts about the individuals. For example, providing insight into a city’s taxi drop-off policies while protecting sensitive information such as location data.
The ability to share and reuse insights derived from data, while at the same time protecting individuals is notoriously hard.
And many of the methods that have been used in the past to share data, while protecting individuals privacy have fallen prey to a range of increasingly sophisticated attacks.
—Gerome Miklau, Tumult Labs
“It’s well understood that re-identification attacks can be very successful and lead to privacy vulnerabilities,” notes Miklau. “Aggregate statistics…are subject to reconstruction attack, even data used to train machine learning models are subject to membership inference attack. Differential privacy is a response to all of these attacks and provides a framework for reliable data sharing.”
How does differential privacy technology work?
Miklau explains the application of differential privacy (DP) means that if one seeks to perform computations on sensitive data, the computation must be rewritten to satisfy the DP standard.
Once we do the computation in this standard-satisfying way, we get output that has a very formal and rigorous guarantee that [this output can’t] be reverse engineered back to individual records or facts, so we can reuse and share that output.
The privacy guarantee stands up in the face of powerful adversaries.
—Gerome Miklau, Tumult Labs
Importantly, it means that every attribute of the individual gets equal protection, so choices don’t have to make between sensitive and non-sensitive data, notes Miklau.“ Differential privacy as a technology for protecting privacy resists both current attacks that we know about and future attacks. It’s also ahead of regulation.”
- DP has been adopted by the U.S. Census Bureau and deemed sufficient to meet U.S. Title 13
- DP has been adopted by the IRS and deemed sufficient to meet U.S. Title 26, and
- DP is widely considered to satisfy GDPR’s anonymization standard
When running DP computation there’s a [tunable] ‘privacy loss parameter’ [the epsilon (ϵ)]…to set policy about how much information goes out when we publish, explains Miklau, and “allowing enterprises to do what we call privacy accounting:” to account for the tradeoff between data privacy and data accuracy.
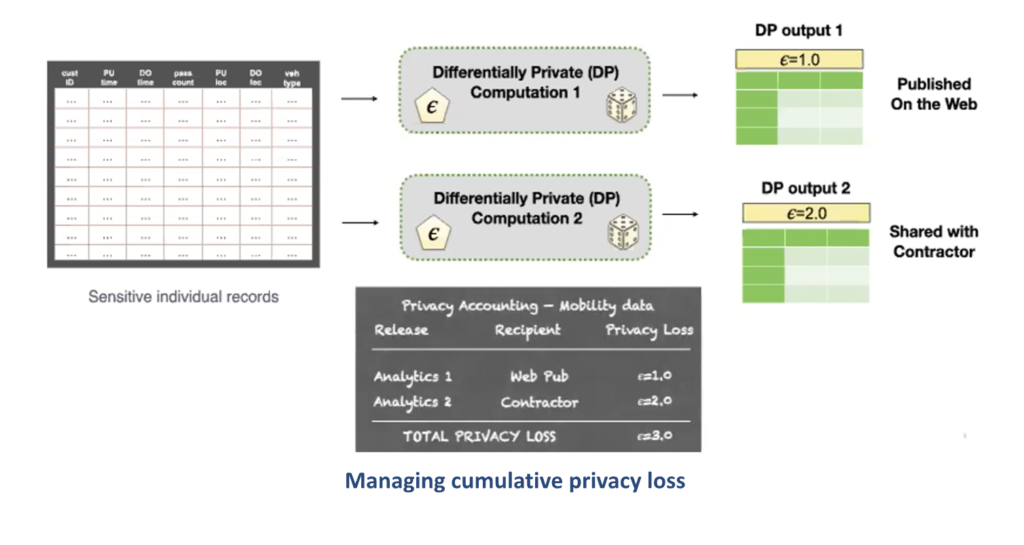
“Major U.S. government agencies are excited about differential privacy for compliant data sharing, says Miklau. “The value drivers include:
- Faster, safer movement of data enabling faster decisions making
- The ability to perform institution-wide privacy accounting, and
- A principled negotiation of privacy. There’s always a tradeoff between the strength of the privacy guarantee and the accuracy of outputs.
Importantly, as Miklau points out, the central use cases is the reuse and repurpose of data. This is valuable internally within a business enterprise as well. “When you have sensitive data…by computing a differential product summary of it, you can then move that around the enterprise much more easily and enable the use of data” for new insight and purpose.
IRS Case Study
The motivation for the collaboration between Urban Institute and the IRS is to advance evidence-based policymaking.
However, full access to these data are only available to select government agencies and the very limited number of researchers working in collaboration with analysts in those agencies.
— Claire McKay Bowen, Urban Institute
To expand access, the Urban Institute came into collaboration with the IRS Statistics of Income Division where it is “developing a synthetic data and differential privacy tools to allow researchers access to sensitive data, while providing robust privacy protections,” says Bowen.
There are two ways in which researchers have accessed data, explains Bowen: 1) from public statistics and data, and 2) the confidential data directly.
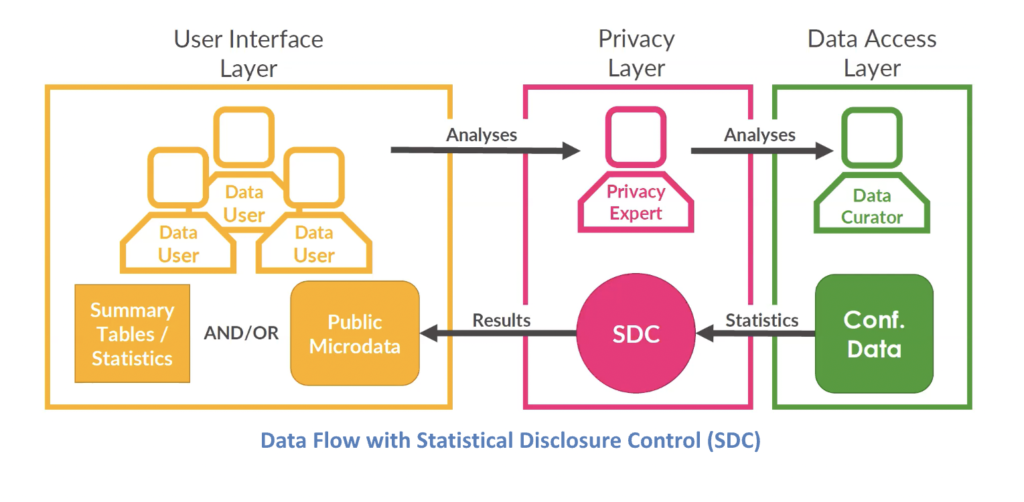
The above diagram describes the flow between the data user to a privacy expert (such as Bowen) and the curator (in this case also the data Steward) the IRS. This scenario is not ideal. As Bowen explains, it is very difficult to get direct access as it is constrained by clearance requirements.
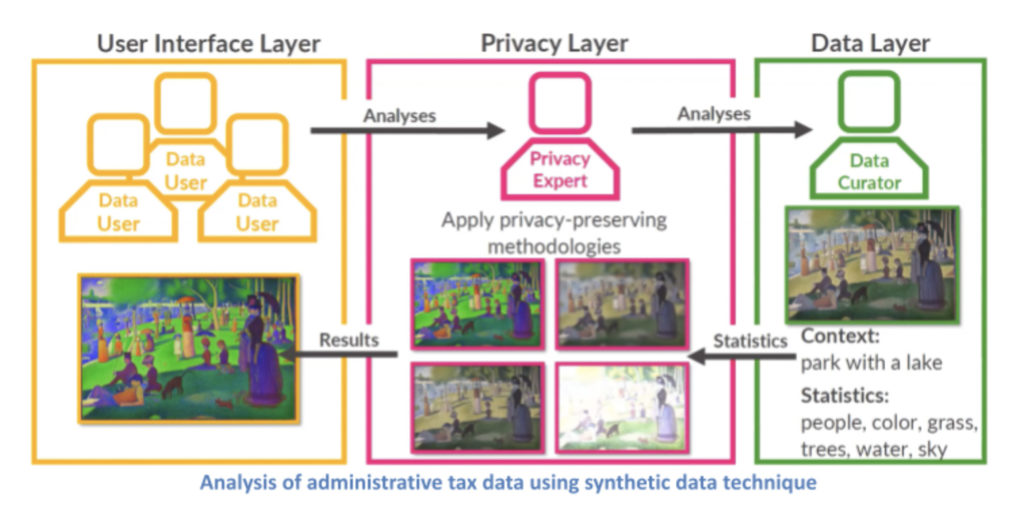
Utilizing public statistics and data “isn’t a great option either. Given the growing threats to public-use micro data (i.e., individual record data) and concern for protecting privacy, it has led to government agencies progressively restricting and distorting the public statistics and data information being released.” Making it much less useful.
To solve this challenge, Urban Institute has devised two approaches.
- Improving the quality of the public data that is released using synthetic data generation technics, and
- Creating a new tier between the public data set and the direct access to data.
The synthetic data generation technique , says Bowen, has allowed organizations like the American Enterprise Institute and the Urban Brooking Tax Policy Center to conduct valuable micro simulation modeling to assess, for example, how much Medicare for all is going to cost the average taxpayer.
As written about here, synthetic data is not actual data taken from real world events or individuals’ attributes, rather it id data that has been generated by a computer to match the key statistical properties of the real sample data. Importantly, it is not the actual data that has been pseudoanonymized or anonymized. It is artificial data that does not map back to any actual person.
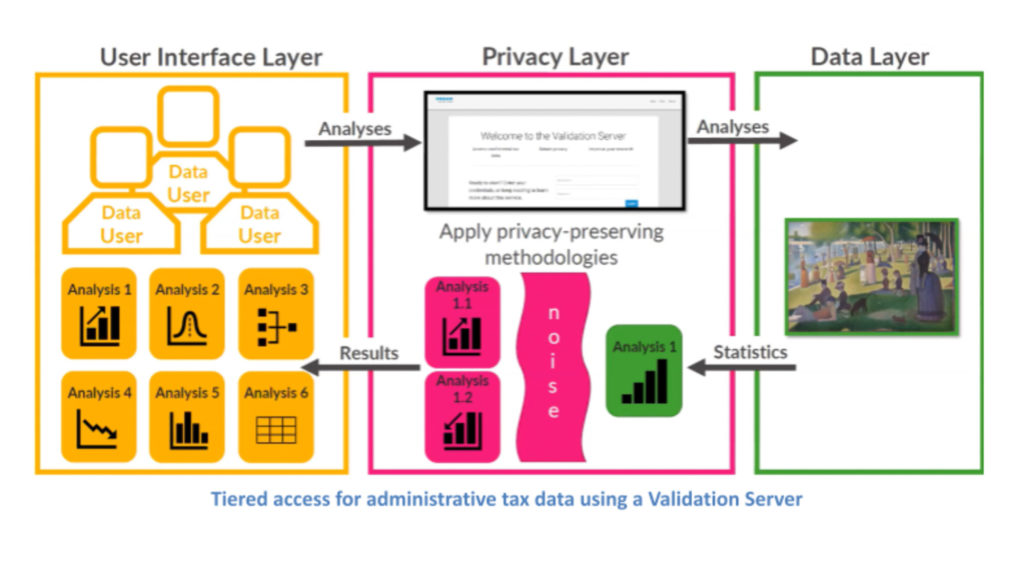
While synthetic data is a great solution for this application, “it’s not perfect, because you don’t know if there’s some other valuable analyses you didn’t quite account for when you built the model,” explains Bowen and this is where the “new tier of access that we’re developing called a validation server” comes in.
In this approach, the researcher i) enters in their analyses, ii) the analyses accesses the actual data iii) the output generated passes through the differential privacy mechanism (the “noise”), and then iv) analyses are provided with privacy protected.
“The privacy-utility tradeoff here is that you’re not looking at the original data but you’re still getting a result that (hopefully) is very similar to the original,” opines Bowen.
Bowen points to commercial use cases: For example, LinkedIn looking for ways to communicate their market data to different departments that didn’t have access to the data or Uber trying to share their ride-share data internally using aggregation techniques to preserve privacy.
U.S. Department of Education case study
“The College Scorecard website is an initiative led by the U.S. Department of Education (DoE) to empower the public to evaluate post-secondary education options more empirically,” explains Machanavajjhala.
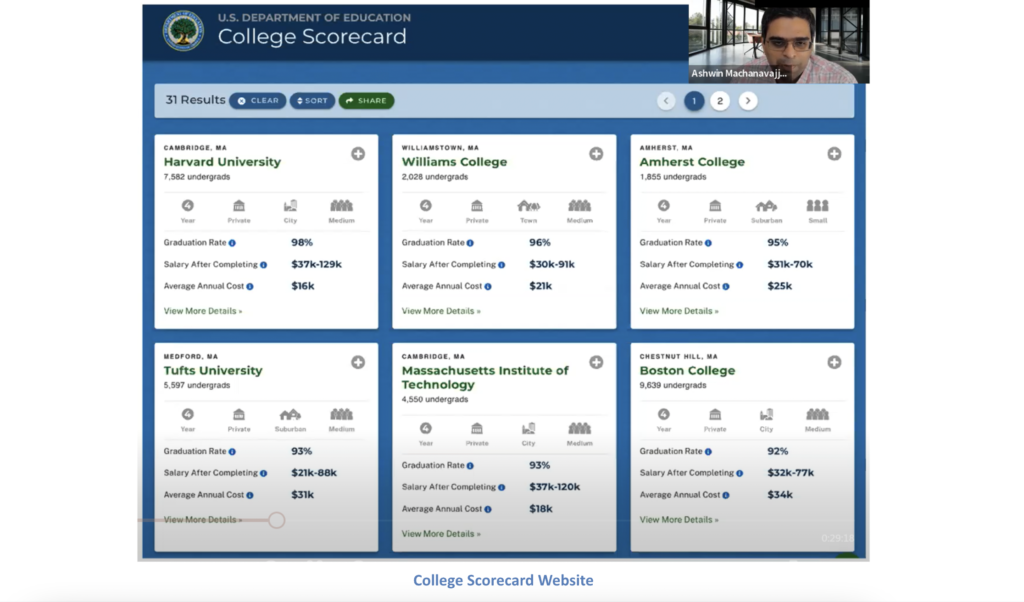
The department education has access to data about college costs, records describing students, and degrees attained, “but they don’t have the most valuable and interesting aspects of the website: the student economic outcomes metrics,” details Machanavajjhala. That information is with the IRS, and consequently, “the DoE must go the IRS and ask for this information every year.”
The IRS cannot just hand over the data to any other agencies as they’re bound by law to protect all information provided by tax returns – even the fact that somebody filed a return.
So, every year, the IRS has to deal with this problem of what should be released to the DoE, and how to transform the data to protect privacy.
—Ashwin Machanavajjhala, Tumult Labs
This challenge, notes Machanavajjhala, is becoming increasingly prevalent since the passage of the Evidence-Based Policy Making Act in 2018 and the consequent intensified requests for data sharing.
“The data custodian [in this case the IRS] is faced with a number of challenges,” says Machanavajjhala. “In past years, data protection was based on simple ad hoc distortion of the statistics and suppression. But the rules used were rendering most of the data useless (with upwards of 70% to 90% of the data redacted).
“Furthermore, the disclosure process was manual, so it was extremely onerous and becoming harder every year as analysts requested ever more data and detailed statistics.”
Solving the data sharing problem
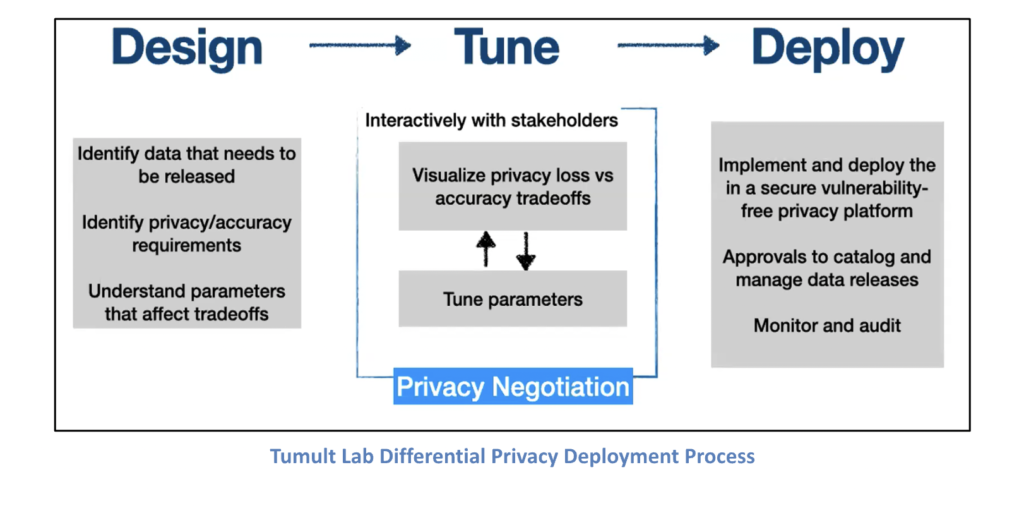
To solve this challenge, Tumult Labs designed a three-step approach:
“Differential privacy is not a single algorithm,” cautions Machanavajjhala. “It’s an entire methodology. So, the right algorithm for your problem may require a significant amount of tuning to ensure the data that is output actually meets the needs of your application.”
Putting this in context of the IRS-DoE data sharing challenge, Machanavajjhala details that the DoE was requesting 10-million statistics involving 5-million students. Each of these statistics were either a count or a median or quantity of different overlapping groups of students. A complex request and very fine grained.
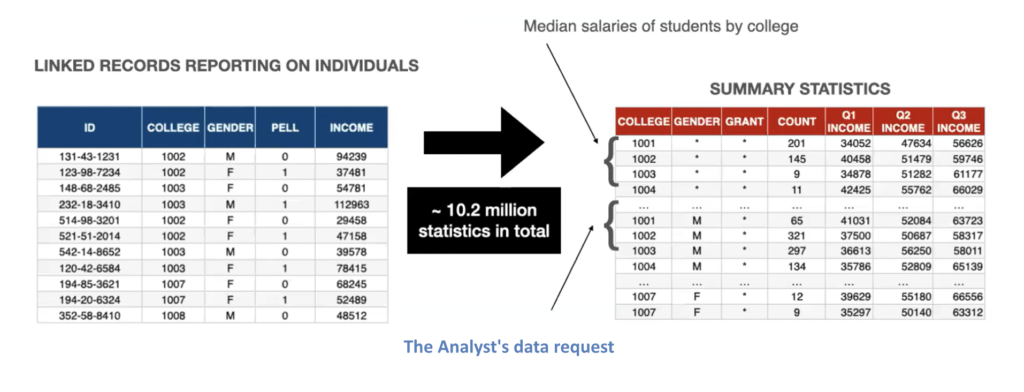
As “any privacy method is going to distort the data in some way…to ensure privacy of individuals but preserve statistics, it is important to know what characteristics analyst care about.” This requires establishing “fitness for use requirements,” which in addition to any specifically requested, will likely include:
- A prioritized list of output statistics
- The least privacy loss +
- As much useful data as possible = (the privacy ϵ “negotiation”)
- Error measures (“privacy accounting”) such as relative error, and number of records suppressed
- Inconsistency between statistics, and
- Ranking inversions
Tumult Lab developed software tools to enable this “negotiation” and enumerate the tradeoffs between privacy and accuracy when tuning the differential privacy “loss parameters (ϵ).”
Importantly, notes Machanavajjhala, deployment, should be community vetted, support peer review, enable safe privacy operations, and ensure there is an approval process to catalog and manage data releases, and audit and monitor them.
Ultimately, the Tumult differential privacy platform provided the IRS with a rigorous, automated, and quantifiable differential privacy guarantee and simplified decision making. All while enabling the release of more student income statistics than ever before with comparable accuracy and power the College Scorecard website.
Automated, quantifiable privacy guarantees with simplified decision making are important attributes for the privacy office and the business in commercial settings. But, as Bowen notes, “most different privacy technology is still found in highly technical papers so getting an expert on your team to filter through and figure out what is applicable what’s not,” is essential.
And as it is new technology, she advises “thinking about what training, education materials, and other support you need to get people up to speed.”


